제2편: 강화학습의 거의 모든것: Multi-armed Bandit
제1편: 강화학습의 거의 모든것 https://wonseokjung.github.io//reinforcementlearning/update/RL-RL1/
제2편: 강화학습의 거의 모든것 : Multi-armed Bandit
Multi-armed Bandit은 아주아주 간단한 Reinforcement 의 문제중 하나이지만,
이 챕터를 다시 읽어보며, 이 간단한 Multi-armed Bandit을 풀기위해 적용된 방법들이 현재 강화학습 이론이 바탕이 되었구나 라고 판단되었다.
그만큼, 매우 중요하니 꼭 볼것!
순서
Multi-armed Bandits
1.A k-armed Bandit Problem
2.Action-value Method
3.The 10-armed Testbed
4.Incremental Implementation
5.Tracking a Nonstationary Problem
6.Optimistic Initial values
7.Upper-Confidence-Bound Action Selection
8.Gradient Bandit Algorithms
Multi-Armed Bandits
Reinforcement learning는 다른 learning과 구분지을수 있는 특징으로는 ,
action을 evaluate 한다는 것이다.
이렇게 evaluate하는 과정은 좋은 behavior을 찾기 위해 active exploration을 한다는 것이ㅏ.
Feedback의 종류가 두가지가 있는데,
-
첫번째는 evaluaute feedback으로 선택된 action에 따라 달라지는 feedback
-
두번째는 intructive feedback으로 선택되어진 action과 독립적인 feedback
이 챕터에서는 Reinforcement learning ( 강화학습 ) 의 evaluate feedback에 대하여 한 상황에 대해서만 행동을 하도록 학습하는
간단한 예제를 통하여 배울 것이다.
1. A k-armed Bandit Problem
K-armed Bandit 의 learning problem은 다음과 같다.
==“Bandit problems embody in essential form a conflict evident in all human action: choosing actions which yield immediate reward vs. choosing actions (e.g. acquiring information or preparing the ground) whose benefit will come only later” - P. Whittle (1980).==
1.k-different option이나 action을 선택할 수 있다.
2.한 번 action을 선택할 때마다 stationary probability distribution에서 numberical reward를 받는다.
3.목표는 한정된 시간동안 expected total reward를 maximize 시키는 것이다.
k-armed Bandit의 의미는 k개의 lever가 있는 slotmachine이다.

http://www.primarydigit.com/
각 action을 선택할때는 machine의 lever를 당기는 것과 같고,
rewar는 jackpot을 터트려 받는 돈과 같다.
action을 select하는 것을 반복하며 reward를 많이 주는 최고의 lever 찾아 승률을 최대화 시킨다.
k-armed bandit problem 에서는 각 action이 선택되었을때, 그 action을 expected 또는 mean reward를 한다.
이와 같은 것을 value of the action ( 그 행동을 한 가치)라고 한다.
그 시간에 선택된 action을 라고 하며, corresponding한 reward를 Reward 라고 한다.
Action a가 선택되었을때의 expected reward를 라고 하며, 다음의 식으로 정의한다.
만약 각 action의 value를 알고 있다면, 가장 높은 reward를 받는 선택만 선택하므로 bandit 문제를 해결할 수 있을 것이다.
여기서는 action value를 모른다고 가정하며,
시간 (time ste t)에서 선택된 action을 estimate value를 를 가 되기를 원한다.
Action value를 측정할때 항상 최소한 하나의 ation은 가장 큰 value를 estimate할것이다. (예를 들어서 10개의 레버를 당겼을때 최소한 한개의 레버는 그중 가장 큰 reward를 줄 것이다.)
위와 같이 가장 큰 value를 선택하는 action을 greedy한 action 이라고 부르며,
greedy 한 action을 선택할때는 exploiting한다고 한다.
반대로, 만약 greedy 하지 않은 action중 하나를 선택한다면 explorating 한다고 한다.
Exploitation으로 한 step에서의 expected reward를 maximize하기위해 greedy action을 선택할 수 있지만,
현재 당장 받는 reward가 적더라도, long term에서는 exploration을 함으로서 더 높은 reward를 받을 수도 있다.
2. Action-value Methods
ACtion 을 선택했을때의 action value를 estimate하는 방법에 대하여 자세히 알아보겠다.
먼저 여기서 True action value의 정의는 action이 선택되었을때의 평균 reward이다.
이 True action value를 계산하는 방법은 실제로 받을 reward를 평균한 값이다.
여기서 은 predicate가 true면 1, 아니면 0이다.
만약denominator가 0이면 는 default value 정의한다.
그리고 denominator가 무한대로 가면 는 $$q_(a)로 converge한다.
이런 방법을 action value를 estimate한 sample-average라고 하며, 이외에도 action value을 estimate하는 방법은 여러가지가 있다.
그렇다면 action을 선택하는 방법에는 무엇이 있을까?
1.
greedy action은 위와같이 정의하며, 는 를 가장 maximize 시켜주는 action.
현재의 정보를 통해 바로 받는 reward를 maximze 하는 action을 선택한다.
2.
가끔 epsilon의 확률로 greedy한 action이 아닌 다른 action을 선택하는 방법이 있다.
exploitation으로 한 step에서의 expected reward를 maximaze하는 action을 선택할 수 있지만, 어쩌면 long term에서는 exploration을
하여 미래에 더 높은 reward를 얻을수도 있을 것이다.
3. The 10-armed Testbed
Greedy와 방법을 실험하기 위해 비교 실험을 하였다.
k-arm bandit ( k = 10)에서 2000개의 데이터를 random 하게 생성하였고,( normal distribution, mean 0, variance 1의 조건)
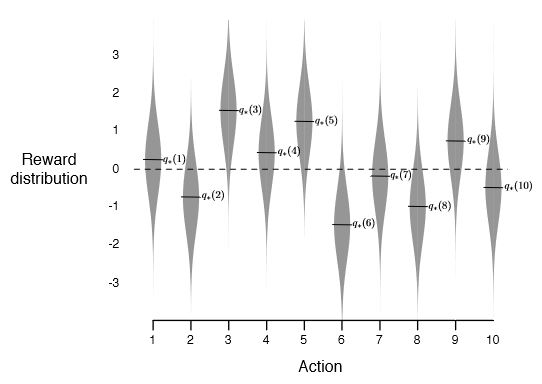
두번째는 greedy method 와 method의 비교이다. (= 0.1 과 = 0.01)
10 Arm bandit에서 sample-average technique를 사용하였다.
아래의 그래프는 experience 에 따라 expected reward가 증가하는 그래프이다.
greedy 가 보다 average reward가 증가하는 량이 느리다.

step 1000에서의 average rewawrd도 greedy방법이 1 정도로 가장 낮다.
gredy action은 suboptimal action에 갇히기 쉽게 때문에 에 비해 성능이 나쁘다.
밑의 graph에서 greedy는 금방 optimal한 action을 찾고 더이상 향상되지 않는다.
는 계속 optimal action 을 찾기 위해 explore하고 개선하여 더 좋은 결과를 보인다.
4.Incremental Implementation
지금까지 다룬 actin-value method는 관찰된 reward를 sample average하여 estimate한 것이다.
좀 더 효율적인 방법으로 action-value를 측정할 수는 없을까?
은 action이 n-1만큼 선택된 후에 estimate 된 action value 이다.
은 다음과 같이 정의할 수 있다.
Obvious implementation은 모든 reward를 기록할때, estimate value가 필요한때 언제라도 사용할 수 있다.
하지만 reward가 늘어날 때마다 memory와 computation이 늘어날 것이다.
하지만 Incremental formular을 사용하면 위의 방식이 필요없다.
의 식을 아래와 같이 바꿀수 있다.

이 Implementation 방법은 과 , 의 메모리만 있으면 된다.
Simple Bandit Algorithm 의 Pseudocode는 아래와 같다.

1.Q와 N을 0으로 초기값을 준다.
2.Action은 로 선택된다.
3.선택된 Action을 통하여 Reward를 받는다.
4.N(A)+1로 N(A)를 업데이트 한다.
5.Reward - Q(A) 값에 1/N(A)를 해준것에 Q(A)를 더해주어 Q(A)를 업데이트 한다.
여기서 Reward - Q(A)는 estimate의 error라고 하며, 다음과 같이 표기할 수 있다.
[ Target - OldEstimate ] 가 estimate의 error이며, 이 error는 step을 진행하면서 Target에 가까이 갈수록 줄어든다.
Target은 이동하여야 하는 바람직한 방향이며,여기서 Target은 n번째의 reward이다.
Step-size parameter는 time step 마다의 incremental method이며, action a 의 n번째 step size는 1/n 이다.
또는 라고 정의하기도 한다.
5. Tracking a Nonstationary Problem
Stationary 한 Bandit problem을 Average하는 방법을 알아보았다.
(여기서 stationary 하다는 것은 reward의 probabilites가 시간에 따라 변하지 않는다.)
Reinforcement learning에서는 가끔 nonstationary한 상황과 마주치는데,
(예를 들어 최근의 받은 reward를 오래전에 받은 reward보다 weight를 더 많이 준다.)
이것을 하는 방법으로 유명한 방법은 ste-size parameter을 조절하는 것이다.
예를 들어, Incremental Update rule ( n-1의 reward의 평균 Qn을 update )
또는 step마다 step-size parameter을 다르게 하는 방법도 있다.
이 방법은 다음과 같이 정의할 수 있다.
여기서 는 이며,
는 weighted average의 과거 reward이다.
위의 식을 풀면 다음과 같이 정의할수 있다.

이것은 weighted average라고 부르는데 weight의 합이 항상 1이 되기 때문이다.

에서 Reward는 n-i에 따라 weighted 되어진다.
6. Optimistic Initial Values
Exploration 방법으로 epsilon-greedy를 사용하여 exploration을 하였는데, 여기서는 꼭 어떠한 epsilon의 확률로
non-greedy한 action을 선택하는 epsilon-greedy 방법을 사용하지 않는다.
다른 방법으로는 Initial action value을 0이 아닌 높은 값으로 주는 것이다.
이것은 action a를 선택할때 starting value가 reward보다 더 크기 때문에 다른 action을 선택하며, 그로 인해 exploration을
encourage하는 효과가 있다.
아래의 그래프는 10-armed bandit 에서 이를 실험한 결과이다.

Optimistic greedy 방법은 action value를 0이 아닌 5로 초기화 해주었고 epsilon 은 0으로 항상 greedy한 action만 선택한다.
그렇기에 초반에 exploration을 비교적 많이 한다.
realistic, epsilon-greedy 방법은 epsilon 값은 0.1이며, 초기 action value 는 0 이다.
두 greedy 방법을 10-armed bandit 에서 실험해본 결과,
초기 (200 steps) 까지는 realistic 방법이 optimistic 방법에 비해 optimal action을 찾을 확률이 더 높았지만,
200steps이후에는 optimistic 방법이 더 좋은 성능을 보였다.
이는 optimistic 방법이 explore를 많이 하기 때문에 처음에는 성능이 떨어지지만, 시간에 따라 exploration이 줄어들기 때문에 결국
더 좋은 성능을 보인다.
7. Upper-Confidence-Bound Action selection
action -value estimation의 정확도는 uncertainty하기에 exploration은 항상 필요하다.
Greedy action은 현재에서 Best한 action을 선택한다.
현재 reward를 가장 많이 받는 action을 선택하는 것이 미래의 reward도 가장 많이 받는 action 이라고 확실할수 있을까?
어쩌면 현재 reward는 작게 받는 action이라도, 미래에는 더 좋은 reward를 받는 action일수도 있다.
Epsilon-greedy action selection은 강제로 non-greedy한 action을 선택한다.
하지만 action을 preference를 하지 않고 무작위로 결정을 한다.
non-greedy action을 선택할때 실제로 optimal이 될 잠재력이 높은 action을 선택하는 것이 더욱 효율적이지 않을까?
위의 식으로 을 추가하여 action을 선택하는 방법을 알아보자
여기서 는 natural logarithm의 t 이며, 는 prior 부터 time t 까지 action a가 선택된 횟수이다.
는 exlporation의 정도를 조정하며, 가 0 일때는 maximizing action을 선택한다.
위와 같은 아이디러를 Upeer confidence bound (UCB)action selection value라고 한다. 여기서 은 uncertainty를 측정 또는 a value의 variance 값을 측정한다.
가 커질수록 uncertainty term이 decrease하며, 아래의 그래프와 같이 perform이 좋아보이지만
사실은 bandit문제를 제외한 다른 reinforcement learning에서는 epsilon-greedy 방법보다 성능이 좋지 않다.

8. Gradient Bandit Algorithms
지금까지는 action의 value를 estimate한 값을 구하였고, action을 선택할때 그 action value를 기준으로 하였다.
다른 approach는 numberical preference를 배우자는 목적이며, ( 각각 action의 preference )
denote는 다음과 같이 로 합니다.
preference가 커지면 그 action은 더 많이 선택될 것이고, 하지만 reward에는 preference가 없다.
Gradient 방법에서는 action을 선택할때 아래와 같이 soft-max distribution을 따른다.
는 time t에서 action a를 선택할 확률이다. 모든 preference의 초기값은 같기 때문에 (예를 들어 ) 초기화 했을때 모든 action은 같은 확률로 선택되어진다.
Stochastic gradient ascent의 idea를 기반으로 natual learning algorithm 이 있다.
각 Step마다, 를 선택한 후 를 받고, 다음의 식을 통하여 preference가 update된다.

은 step-size parameter임 time t를 포함한 모든 reward의 average는 위에서 봤던
update rule에 의하여 계산된다.
는 reward가 비교되는 baseline으로 사용된다.
만약 그 reward가 baseline보다 높으면 가 선택될 확률이 높아지며, 반대로 reward가 baseline보다 낮으면 그 가 선택될 확률이 줄어든다.
아래의 그래프는 baseline을 사용했을때와 사용하지 않았을때의 비교이다.
steps에 따라 optimal action을 선택할 확률인데,

baseline을 사용한 경우가 그러지 않았을때보다 월등히 optimal action을 선택할 확률이 높았다.
정리
지금까지 Multi-armed Bandit에 대하여 알아보았다.
1.A k-armed Bandit Problem
2.Action-value Method
3.The 10-armed Testbed
4.Incremental Implementation
5.Tracking a Nonstationary Problem
6.Optimistic Initial values
7.Upper-Confidence-Bound Action Selection
8.Gradient Bandit Algorithms
이 챕터에서 Multi-armed bandit 문제를 풀기 위하여 여러가지 방법이 시도 되었고,
이는 고전알고리즘의 전체의 아이디어와 동일하다고 생각한다.
다음 챕터는 MDP ( Markov decision process )로 Bandit 처럼 action을 선택했을때 reward만 받는것이 아닌,
action을 선택하므로서 state ( 상태 ) 가 달라진다.
여기서 Agent, State, Environment의 개념이 추가되는데,
자세한 것은 다음 챕터에 알아보겠다.
Reference
- Reinforcement Learning: An Introduction Richard S. Sutton and Andrew G. Barto Second Edition, in progress MIT Press, Cambridge, MA, 2017